In the previous post, I noted that a chemistry publisher is about to repeat an earlier experiment in serving pre-prints of journal articles. It would be fair to suggest that following the first great period of journal innovation, the boom in rapid publication “camera-ready” articles in the 1960s, the next period of rapid innovation started around 1994 driven by the uptake of the World-Wide-Web. The CLIC project[cite]10.1080/13614579509516846[/cite] aimed to embed additional data-based components into the online presentation of the journal Chem Communications, taking the form of pop-up interactive 3D molecular models and spectra. The Internet Journal of Chemistry was designed from scratch to take advantage of this new medium.[cite]10.1080/00987913.2000.10764578[/cite] Here I take a look at one recent experiment in innovation which incorporates “augmented reality”.[cite]10.1055/s-0035-1562579[/cite]
The title is interesting: “Combination of Enabling Technologies to Improve and Describe the Stereoselectivity of Wolff–Staudinger Cascade Reaction“. One of these technologies relates to “microwave-assisted flow generation of primary ketenes by thermal decomposition of α-diazoketones at high temperature”, but the journal presentation itself attempts the “faster interpretation of computed data via a new web-based molecular viewer, which takes advantage from Augmented Reality (AR) technology“. To access this component directly, go to the link https://leyscigateway.ch.cam.ac.uk/staudinger/ It is not incorporated into the journal infrastructures as the CLIC project attempted, but is perhaps closer to the model I noted in the previous post of supporting (FAIR) data associated with the article and hosted separately from the journal.
What happens next depends rather on the Web browser you are using. With many browsers and tablets, a conventional 3D molecular presentation appears; there is no button present where the red arrow points. You will find out this is because “Augmented Reality is not available in your browser, as the getUserMedia() API is not supported“
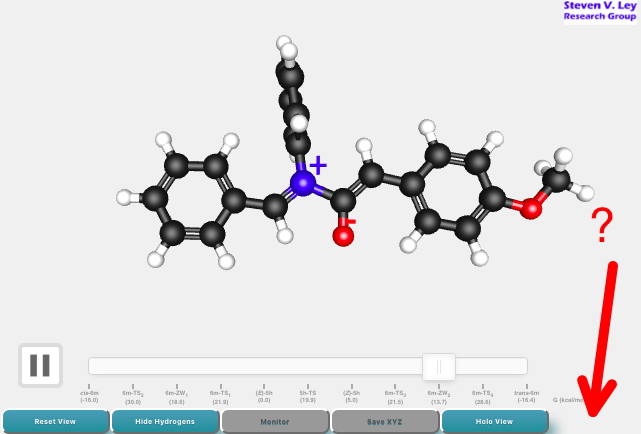
Some browsers (the latest Opera, FireFox, Chrome) do support this feature, and a new AR button appears. Selecting this now layers the video from the device camera onto the 3D molecular model; the molecule now floats in the scene captured by the camera (which in the case below is the room I am sitting in). After a few seconds you are urged to “point the camera towards the AR marker”. The supporting information contains such AR markers as a navigation aid for the 3D coordinates contained there. An example is:

If this marker is now brought into the camera view (by printing it, sic) and holding it in front of the camera image, the marker resolves into further data relevant to the molecule of interest, layered into the existing scene of the room and the molecule. For the marker above, it resolves to a reaction energy profile which reveals where the specific molecule sits energetically in terms of the overall reaction.
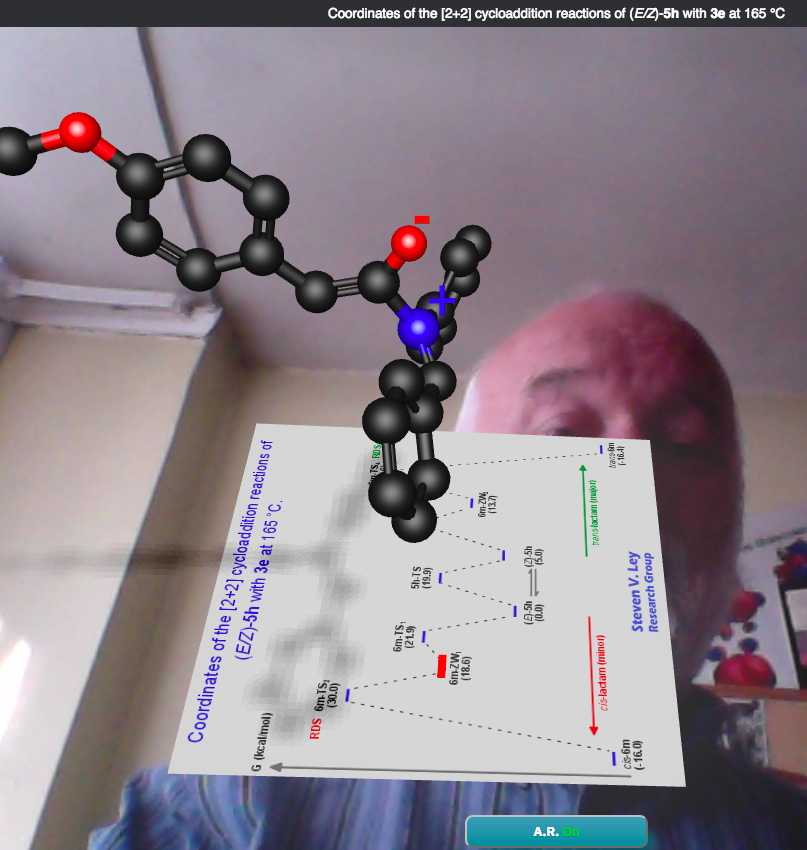
This layering of “heads up” molecular data into a scene comprising a 3D molecular model and the human viewer of that molecule captured in video is what defines the concept of “augmented reality” (the data being the augmentation, rather than the human).
Having now tried it out, I was left wondering whether this truly was a great advance in enabling technology for chemistry journals. The role of the camera seems primarily to capture the AR markers contained in the supporting information; the presence of the reader in the video image apparently inspecting the molecule could be regarded as a distraction. The AR markers (QR codes) are merely visual representations of a URL, which in the form of a DOI (as used in this blog) to locate data is rather more familiar to most readers. The DOI, by the way, carries further information in the form of metadata, and which when sent to e.g. DataCite, enables the data to be found. Does the data need to be layered onto the molecule (and apparently floating in front of the reader) to become usable? Could it instead be placed in a pop-up or separate window of its own (as the 1994 CLIC project achieved)? Do the AR markers enable the data to be FAIR? One can Find the data (albeit only by reading and printing the supporting information) and view it in the AR scene, but is it Accessible (can one access the underlying numerical data?) or Interoperable (place it into another program) or Re-usable?
As with all enabling technologies, one has to always ask if that technology helps or hinders. Or is the principle of KISS (keep it simple) sometimes better? It is however good to see research groups experimenting with these themes and meanwhile readers can judge for themselves whether “heads up” AR augmentation of the data describing research is indeed the next big thing.