The title of this post refers to the site http://howopenisit.org/ which is in effect a license scraper for journal articles. In the past 2-3 years in the UK, we have been able to make use of grants to our university to pay publishers to convert our publications into Open Access (also called GOLD). I thought I might check out a few of my recent publications to see what http://howopenisit.org/ makes of them.
This was catalysed by an article which revealed that UK universities spent £9M in 2014 on the purchase of such openness. One of the “challenges” identified is the difficulty in converting such payment into an article that actually is open. Apparently, publishers make not a few mistakes in their quality controls in ensuring it is so, relying on irate authors informing them of such mistakes. This can be quite tedious to do, and so a tool that largely automates this checking is most useful. So here we go.
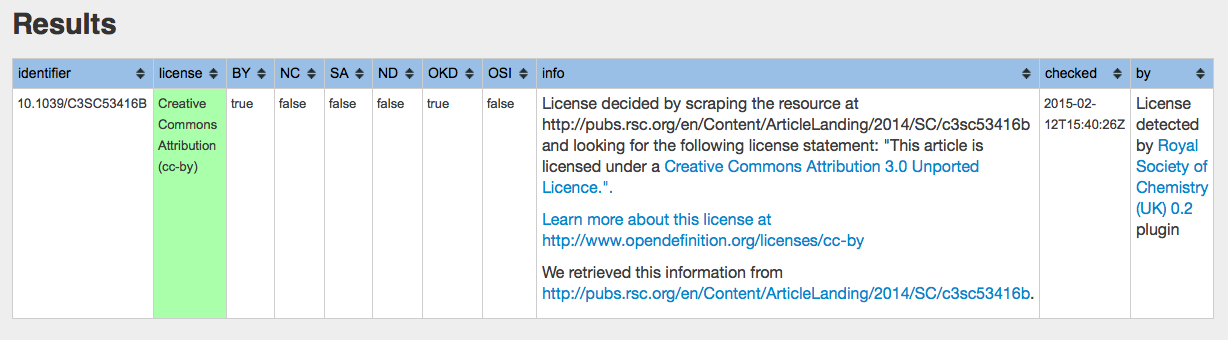
doi: 10.1039/C3SC53416B[cite]10.1039/C3SC53416B[/cite] This is a good start. The output looks like thus. Green is GOLD so to speak. Well done the Royal Society of Chemistry.
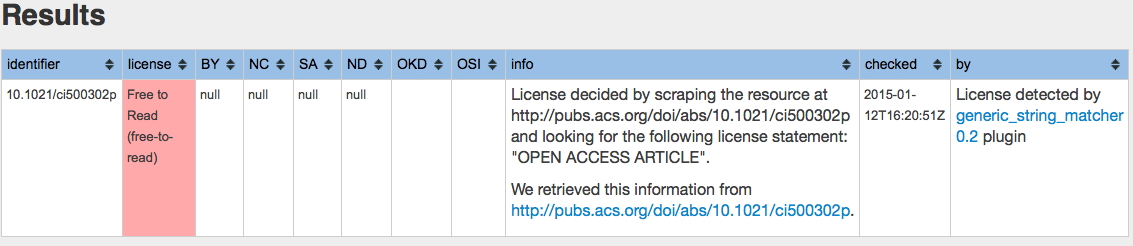
doi: 10.1021/ci500302p[cite]10.1021/ci500302p[/cite] from the ACS this time. Pink, but at least free to read. Quite what that means is less certain. There is an adage, “the right to read means the right to mine” presumably means this article is OK to mine, but then why does it not say so?
doi: 10.1002/anie.201405238[cite]10.1002/anie.201405238[/cite]. Pink again, but the colour now simply means no information about the license could be obtained from the publisher (Wiley).
I ran a few more and sadly the third of the above, “no information” was the most common response. And the legal response is invariably that if no information can be obtained, the answer is NO, it is not free to read. In other words, not providing a license is just as bad as saying it’s not free to read.
Article aggregators such as Symplectic do not yet perform the service above (which to be fair is still in beta), and so I cannot yet check how many GOLD articles there are to my name. I think it should be about 8, and I might add that the time I have to spend in arranging for this to happen is not negligible. Hell, I could probably have found a few more reactions mechanism in the time I have spent on achieving GOLD. This is one of those topics which would be interesting to revisit say in five years time to see how the world has changed. So I leave this little time capsule and will update it then!
Egon Willighagen recently gave a presentation at the RSC entitled “The Web – what is the issue” where he laments how little uptake of web technologies as a “channel for communication of scientific knowledge and data” there is in chemistry after twenty years or more. It caused me to ponder what we were doing with the web twenty years ago. Our HTTP server started in August 1993, and to my knowledge very little content there has been deleted (it’s mostly now just hidden). So here are some ancient pages which whilst certainly not examples of how it should be done nowadays, give an interesting historical perspective. In truth, there is not much stuff that is older out there!
This page was written in May 1994 as a journal article, although it did have to be then converted into a Word document to actually be submitted.[cite]10.1039/C39940001907[/cite] Because it introduced hyperlinks to a chemical audience, we wanted to illustrate these in the article itself! Hence permission was obtained from the RSC for an HTML version to be “self-archived” on our own servers where the hyperlinks were supposed to work (an early example of Open Access publishing!). I say supposed because quite a few of them have now “decayed”. We were aware of course that this might happen, but back in 1994, no-one knew how quickly this would happen. What is interesting is that the HTML itself (written by hand then) has survived pretty well! I will leave you to decide how much the message itself has decayed.
This HTML actually predates the above; it was written around November 1993 and represented the very first lecture notes I converted into this form (on the topic of NMR spectroscopy). A noteworthy aspect is the scarce use of colour images. At the start of 1994, the bandwidth available on our campus was pretty limited (the switches were 10 Mbps only) and a request went out to reduce the bit-depth of any colour images to 4-bits to help conserve that bandwidth! I rather doubt anyone took much notice however, and the policy was forgotten just a few months later.
In 1996, I had two visitors to the group, Guillaume Cottenceau, a french undergraduate student, and Darek Bogdal, a Polish researcher who wanted to learn some HTML. Together they produced this, which was an interactive tutorial to accompany the NMR lecture notes previously mentioned. These pages introduce the Java applet (yes, it was very new in 1996), which Guillaume had written and which Darek then made use of. And hey, what do you know, the applet still works (although you might have to coerce your browser into accepting an unsigned applet).
Here is a programming course that I had been running with Bryan Levitt for a few years, now recast into HTML web pages some time in 1994-5. This particular project I still hold dear, since it expanded upon the NMR lectures by getting the students to synthesize a FID (free induction decay) using the program they wrote, and then perform a Fourier Transform on it. I even encouraged students to present their results in HTML (I cannot now remember how many did). This link is to the computing facilities we offered students in 1994 for this project, ah those were the times! In 1996, the programming course was replaced by one on chemical information technologies, and here students were most certainly expected to write HTML. Some of the best examples are still available. And to illustrate how things happen in cycles, that course itself is now gone to be replaced by, yes, a programming course (but using Python, and not the original Fortran).
In tracking down the materials for the programming course described above, I re-discovered something far older. It is linked here and is (some of) the Fortran source code I wrote as a PhD student in 1974 1972.[cite]10.5281/zenodo.19061[/cite] So I will indulge in a short digression. My Ph.D. involved measuring rate constants, and the accepted method for analysing the raw kinetic data was using graph paper. For first order rate behaviour, this required one to measure a value at time=∞, which is supposed to be measured after ten half-lives. I was too impatient to wait that long, and worked out that a non-linear least squares analysis did not require the time=∞ value; indeed this value could be predicted accurately from the earlier measurements. So in 1974, I wrote this code to do this; no graph paper for me! Also for good measure is a least squares analysis of the Eyring equation. And you get proper standard deviations for your errors. In retrospect I should have commercialised this work, but in 1974, almost no-one paid money for software! What a change since then. I must try recompiling this code to see if it still works! And for good measure, here is a Huckel MO program I wrote in 1984 or earlier (I did compile this recently and found it works) and here is a little program for visualising atomic orbitals.
In January 1994, I was asked to create a web page for the WATOC organisation. This certainly predated the web sites for e.g. the RSC, the ACS, indeed famous sites such as the BBC and Tesco (a large supermarket chain) which only started up in mid 1994. The WATOC site itself moved a few years ago.
This is one of those wonderfully naive things I started in 1994, and which did not last long (in my hands). Nowadays, the concept lives on as MOOCs. Note again the almost complete expiry of the hyperlinks.
This is a project we also started in 1994, Virtual reality[cite]10.1016/0263-7855(95)00053-4[/cite],[cite]10.1016/S0166-1280(96)90535-7[/cite]. The idea was that if HTML was text-markup, VRML was going to be 3D markup. VRML itself never quite caught on, but it is having a new life as a 3D printing language!
And by 1995, I felt confident enough in my ability to (edit) HTML, that we started a virtual conference in organic chemistry (we did four of them in the end). I remember the first one involved contributors sending me a Word version of their poster, and I did all the work in converting it into HTML. Such virtual conferences still run, but in truth most participants still prefer to travel long distances to go drink a beer with their chums, rather than hack HTML.
I am going to stop now, since this is far too much wallowing in the past. But at least all this stuff is not (yet) lost to posterity.
Science is rarely about a totally new observation or rationalisation, it is much more about making connections between known facts, and perhaps using these connections to extrapolate to new areas (building on the shoulders of giants, etc). So here I chart one example of such connectivity over a period of six years.
The story starts with this article[cite]10.1002/anie.200902125[/cite], a preview talk about which (Hypervalent Carbon Atom: “Freezing” the SN2 Transition State) I actually saw at an ACS conference a year or so earlier. When the article was published, Steve Bachrach blogged about it, noting the claim for pentavalent carbon. The semantics of a valency vs a coordination are subtle, and I was not convinced that this frozen transition state deserved its elevation from penta-coordinate to pentavalent. After some discussion on Steve’s blog, I built upon these ideas with a few thoughts of my own on the present blog and then wondered whether they could be finally distilled into a more formal publication (testing the precedent in some ways of whether collaborative and public discussions of ideas could be published formally, or whether they would be rejected as having been already “published”). Well, these final distilled thoughts were indeed published in 2010[cite]10.1038/nchem.596[/cite], including their genesis in Steve’s blog (I wanted to put blogs more firmly into the acceptable scientific circle). This article included one species (numbered 5 in that article in 2010[cite]10.1038/nchem.596[/cite]) and pointed out an analogy to replacing CH2+ by e.g the isoelectronic BH1+, in as much as an example of the latter is indeed known as a stable crystalline compound.[cite]10.1016/0022-328X(94)05089-T[/cite]. Iso-electronics is a very fruitful source of connections in chemistry!
Matters rested there until yesterday, when I spotted this on Steve’s blog where he discusses this recent article on the structure of the benzene dication.[cite]10.1021/ja412109h[/cite] Hey presto, there is that molecule again, but now there is firm experimental evidence of its existence! It was I think rather too much to expect the authors of this article to have spotted the connection to mine (although as it happens, both address the issue of complexes to He). The relationship between CH2+ and BH1+ is a little more subtle. From my point of view, it is always worth trawling through the crystal structure database in favour of evidence for hypothetical species (or their isoelectronic substitutions), and so it proved in this case!
There are other connections possible. Thus the dication of benzene has a (higher energy) isomer which is in fact a 4π antiaromatic species which avoids this antiaromaticity by a geometric distortion, with two C-H bonds bending above and below the ring. Such avoided antiaromaticity has been noted elsewhere here.
There is one final connection for me to make. My 2010 article[cite]10.1038/nchem.596[/cite] contained one of my interactive tables containing the data for the various structures (yes, although its data, you will need to have a subscription to the journal to access it). As it happens, last year we wished to reprise this style of publication, but as I blogged at the time, the journal had changed its production processes, and they could no longer offer me that opportunity. Some quick thinking came up with a replacement, which we now use extensively.[cite]10.1039/C3SC53416B[/cite] So the chain of connections resulting from that original talk some six years ago continues.
<
p>As for that chain, it arose distressingly randomly. I do not routinely read the entire ToC of JACS and so would not have discovered[cite]10.1021/ja412109h[/cite] the connection by that route. Fortunately, Steve Bachrach does and helped me make that connection to the molecule shown above. Although I did spend a few minutes thinking to myself “does that structure ring any bells?”. Fortunately, one did (eventually) ring. But for every connection made in this wonderfully human manner, I cannot help but think how many are not! However, if connections were much easier to make, could we as humans cope with the overwhelming deluge of new ideas?
OK, you have to be British to understand the pun in the title, a famous comedy skit about four candles. Back to science, and my mention of some crystal data now having a DOI in the previous post. I thought it might be fun to replicate the contents of one of my ACS slides here.
Firstly, a DOI is one implementation of a more generic (and quite old) concept known as a Handle. This is one form of a persistent digital identifier. Article DOIs have been in common use for at least ten years now, and even new chemistry students know about them!‡ A DOI points to an article in a journal? Not quite as it happens, but in fact it could be a whole lot more that a DOI could lead to! Let me explain by showing you five examples:
doi.org/10042/26065 resolves to a landing page. Crucially, this is NOT the article itself, which may remain obstinately behind a paywall to which you have no access.
doi.org/10042/26065?locatt=id:1 resolves to the first file matching ID=1 that may be present off the landing page, and hence allowing a machine action to retrieve it.
doi.org/api/10042/26065 will return the JSON-encoded full handle record for processing in Javascript, so that a machine now has access to all the information it might need to perform a machine action.
Now, items 2-5 are not generally available; they work only on our servers. We have placed them there to show how item 6 of the Amsterdam Manifesto could be made to work. There are other ways of course. But you can see them in action here[cite]10.1039/C3SC53416B[/cite] (the article is open access, so you should not get any paywall behaviour from the landing page).
‡Postscript. A few days ago, I asked my group of 1st year undergraduate students how they might go about tracking down a journal article from its authors, the journal name and the page numbers. The most common reply was “Google it”. Next came “go to the library and find it on the shelves”. One replied “from its DOI” (that student had done an internship in a pharma company before joining us). I used to teach a chemical information course here[cite]http://doi.org/10042/a3v06[/cite] between 1996 – 2010 where this sort of stuff was a staple. That course is no longer taught. Hence the aforementioned replies!
I have mentioned the Amsterdam manifesto before on these pages. It is worth repeating the eight simple principles:
Data should be considered citable products of research.
Such data should be held in persistent public repositories.
If a publication is based on data not included with the article, those data should be cited in the publication.
A data citation in a publication should resemble a bibliographic citation and be located in the publication’s reference list.
Such a data citation should include a unique persistent identifier (a DataCite DOI recommended, or other persistent identifiers already in use within the community).
The identifier should resolve to a page that either provides direct access to the data or information concerning its accessibility. Ideally, that landing page should be machine-actionable to promote interoperability of the data.
If the data are available in different versions, the identifier should provide a method to access the previous or related versions.
Data citation should facilitate attribution of credit to all contributors
I just gave a talk at the ACS meeting in Dallas which touched upon the need to emancipate data according to these principles. My talk, in case you are interested, focused particularly upon item 6 above.[cite]http://doi.org/10042/a3uza[/cite]
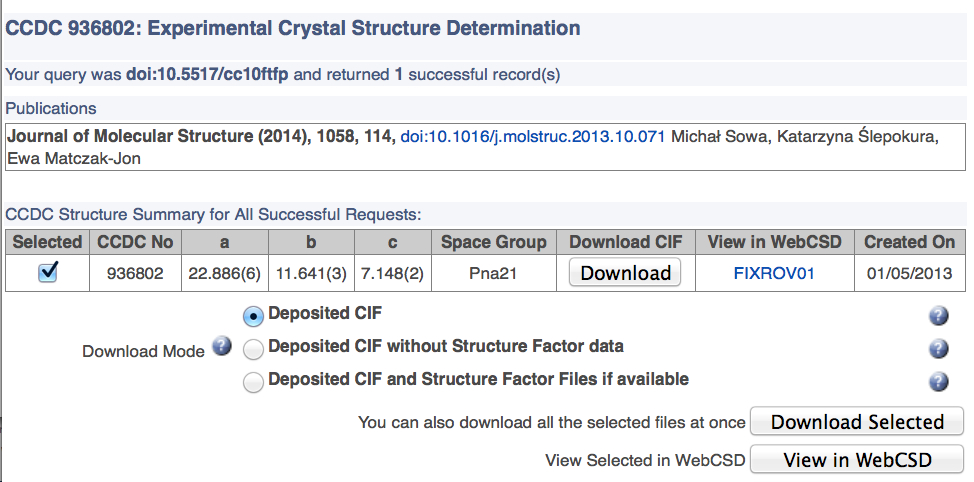
Just after my talk I heard that crystallographic data was about to be emancipated (my phrase) and so I was interested to find out what this might mean, and how many of the above principles were being adhered to. Indeed, it is an interesting test to apply to any chemistry data that you might find out there. Thus 10.5517/cc10ftfp[cite]10.5517/cc10ftfp[/cite] is the DOI of a recently published crystal data structure. This adheres to points 1-3 and 5 above, and probably also 8. As I have already noted, 6 is the interesting one! So let’s go to the landing page and see what we find.
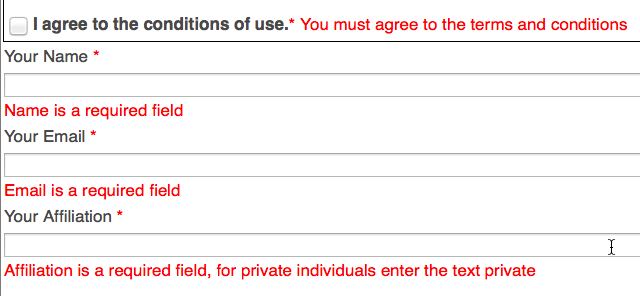
Firstly, note that you do not need any sort of access code to get to this page, it is open to all. But it is after all just a landing page, not actual data. Next, click on the Download button, and you get asked to identify yourself by providing a name, email address and affiliation as mandatory fields, as well as agreeing to conditions of use. I reproduce these conditions here:
“Individual CIF data sets are provided freely by the CCDC on the understanding that they are used for bona fide research purposes only. They may contain copyright material of the CCDC or of third parties, and may not be copied or further disseminated in any form, whether machine-readable or not, except for the purpose of generating routine backup copies on your local computer system“.
As with most such conditions, it is what one cannot do that is most interesting.
Teach, as for example incorporating the data into lecture notes
Make a copy, e.g. to place into this blog (is this for research purposes?)
Do bona fide research purposes in fact allow a copy to be made, or does the second sentence over-ride the first in this regard, since it lists exclusions and research copying is not an exclusion.
Judging from the landing page, it is pretty much impossible for any machine action to take place (item 6 in the Amsterdam manifesto). Even though the data is machine actionable, the landing page pretty much prevents this from happening.
What did cause my eyebrows to shoot up was that I have to reveal my full identity and affiliation (which appears not to be actually checked) in order to get the data. Think about this. Do journals ask for this information when you download an article from them? (OK, they probably know your affiliation). Which scientist is reading which article (or viewing which data) could be construed as sensitive information after all. So why in order to acquire crystal data do you have to provide personal information? Surely, looking at data should be a private process if one wants it to be?
The release of crystal data in this manner, with a decent partial adherence to the Amsterdam Manifesto is an excellent start; this data after all is well curated and of high value. But I must call upon CCDC to rethink that landing page, the conditions of use and the mandatory gathering of personal information. Not quite there yet!
I am at the ACS meeting, attending a session on chemistry and the Internet. This post was inspired by Chemicalize, a service offered by ChemAxon, which scans a post like this one, and identifies molecules named. I had previously used generic post taggers, which frankly did not work well in identifying chemical content. So this is by way of an experiment. I list below some of the substances about which I have blogged, to see how the chemicalizer works.
Mauveine
Copper phthalocyanine
Lapis Lazuli (this is a difficult one, since the active ingredient is actually trisulfide radical anion or S3-.; lets see if any of that is picked up!)
Cyanohydrin (a generic term, but more specifically HCN + Formaldehyde)
diberyllium
Calixarene (another generic term)
1,3-dimethylcyclobutadiene and carbon dioxide
Z-DNA and Z-d(CGCG)2
Cyclohexane, cyclohexene, cyclohexadiene and benzene (the third of these is ambiguous as I have written it)
CH3NO (a formula, with many isomers of course)
Dicarbon or C2 and a cyonium cation or CN+
That should suffice to see how such a list can be chemicalized.
The bimolecular nucleophilic substitution reaction at saturated carbon is an icon of organic chemistry, and is better known by its mechanistic label, SN2. It is normally a slow reaction, with half lives often measured in hours. This implies a significant barrier to reaction (~15-20 kcal/mol) for the transition state, shown below (X is normally both a good nucleophile and a good nucleofuge/leaving group, such as halide, cyanide, etc. Y can have a wide variety of forms).
The Sn2 transition state
This transition state is normally regarded as the only situation in which carbon can sustain penta-coordination (there are some exceptions), and this is often contrasted with the analogous situation for silicon, which demonstrates an abundance of stable penta- (and hexa-)coordinate (crystal) structures. Perhaps inevitably therefore, chemists have set themselves the goal of capturing a penta-coordinate carbon, not as a transition state with fleeting lifetime, but as a stable (and perchance crystalline) species. The best strategy is to explore potential systems computationally, and the latest report of such an exploration has some suggestions for synthesis (Pierrefixe, S. C. A. H.; van Stralen, S. J. M.; van Strale, J. N. P.; Guerra, C. F.; Bickelhaupt, F. M., “Hypervalent Carbon Atom: “Freezing” the SN2 Transition State,” DOI: [cite]10.1002/anie.200902125[/cite]). Their suggestion corresponds to Y=CN and X=At (Astatine), a rather esoteric combination it has to be said. In the manner of the blogosphere, Steve Bachrach has noted this report in his own blog, where a discussion has opened up on the origins of why carbon can be regarded as abnormal (at least compared to silicon), and more particularly whether such a species should be regarded as merely hypercoordinate, or as Bickelhaupt and co-workers suggest, hypervalent.
In fact, such reports are not new. As I note in the discussion of Steve’s blog, a crystalline structure of a hexa-coordinate carbon compound was reported in 2008 (DOI: [cite]10.1021/ja710423d[/cite] (below), and it is also tentatively described as possibly hexavalent near the end of the article! I shall return to this compound in the second part of this post.
Hexa-coordinate carbon
The astatine system reported above is unusual, and it really only contains three carbon-carbon bonds surrounding the pentacoordinate carbon. The compound above contains only two such C-C “bonds”. It would be perhaps more interesting to ask if one could design a compound with five C-C bonds surrounding the putative pentacoordinate atom. Whilst mulling over Steve’s post, and pondering my contribution to that blog, a colleague in my department wandered into my office (my door is almost always open) and without saying a word, he wrote a structure on my blackboard (yes, I really do have such). He then walked out (almost; I believe he did mutter perhaps two words before leaving). He had sketched the key feature of an article by Ethan L. Fisher and Tristan H. Lambert entitled Leaving Group Potential of a Substituted Cyclopentadienyl Anion Toward Oxidative Addition (DOI: [cite]10.1021/ol901598n[/cite]). This triggered the following question in my mind: could the aromatic cyclopentadienyl anion act as the X group in the pentacoordinate carbon example above? The essential property of group X is that it must be big! Well, cyclopentadienyl can be made big! It would also achieve the purpose of forming a penta-coordinate carbon with five C…C bonds.
So in it goes for a B3LYP/6-311+G(2df) calculation. Surely, the life of a computational chemist is an easy one; all one has to do is wait a few hours (or, with a large basis set, days) for an answer. The result is shown below.
The SN2 reaction captured with cyclopentadienyl anion
The key vibrational mode (which you can see animated if you click on the image above) has a wavenumber of 194 cm-1 (B3LYP/6-311+G(2df); other basis sets show similar values). It corresponds to the SN2 mode, and is what we normally think of as the transition or reaction normal mode for this reaction. But in this case, it is not an imaginary mode, but a real mode! The SN2 has been (virtually) captured for a penta-coordinate carbon with five C…C interactions. How does it compare with the astatine system noted in [cite]10.1002/anie.200902125[/cite]? Well, unfortunately, the umbrella-mode for that system is only reported as a force constant without mass weighting, so it cannot be compared to the mass-weighted value we have here. The calculation is digitally archived (e.g. as 10042/to-2407 or 10042/to-2415) so you can analyze it for yourself!
An obvious question to ask is what the nature of the axial bonds for X=cyclopentadienyl is. Is the central carbon hypercoordinate, or hypervalent, or both? But this blog is quite long enough already, and so this will all be discussed in part 2, to follow shortly.
Oh, one final comment. The issue of hypervalency and hypercoordination of carbon has previously been discussed largely in conventional scientific publications (for which DOIs are provided above). The forum moved to Salt Lake City in the USA, where some of the results were presented orally at the ACS spring conference in 2009. Now that it has been formally published, it has been taken up by Bachrach in his blog, where some of the discussion has continued. So where should I have presented the present result? In the primary scientific literature? Or perhaps another ACS meeting? Well, here it is in another blog (I have been variously told I am either brave or very foolish for doing so!). And as I write this, of course it is not peer reviewed (but there is nothing to stop people from commenting on this of course, as has happened in Bachrach’s blog). Will it “count” here – in other words, does it (yet) have any scientific respectability? Should blogs report new scientific results, or merely be reserved for commenting on such results which have been reported in the “proper scientific manner”? Will indeed this result appear in the future in the scientific literature under different authorship, but with no accreditation for this blog? If I do choose to “write it up properly” (assuming the journals now let me), can I cite this blog in the way one can cite the ACS conferences? I do not suppose many people know what the answers are to all these questions. Perhaps the appearance of this post might provide some?
We recently developed a new computational chemistry practical laboratory here at Imperial College. I gave a talk about it at the recent ACS meeting in Salt Lake City. If you want to see the details of the lab, do go here. The talk itself contains further links and examples. Perhaps here I can quote only the final remark, namely that computational chemistry can now provide chemical accuracy for many problems, including spectroscopy and mechanism, and that the basic tools for doing it can easily be carried around in a backpack! Or, perhaps in the not to distant future, an iPhone!