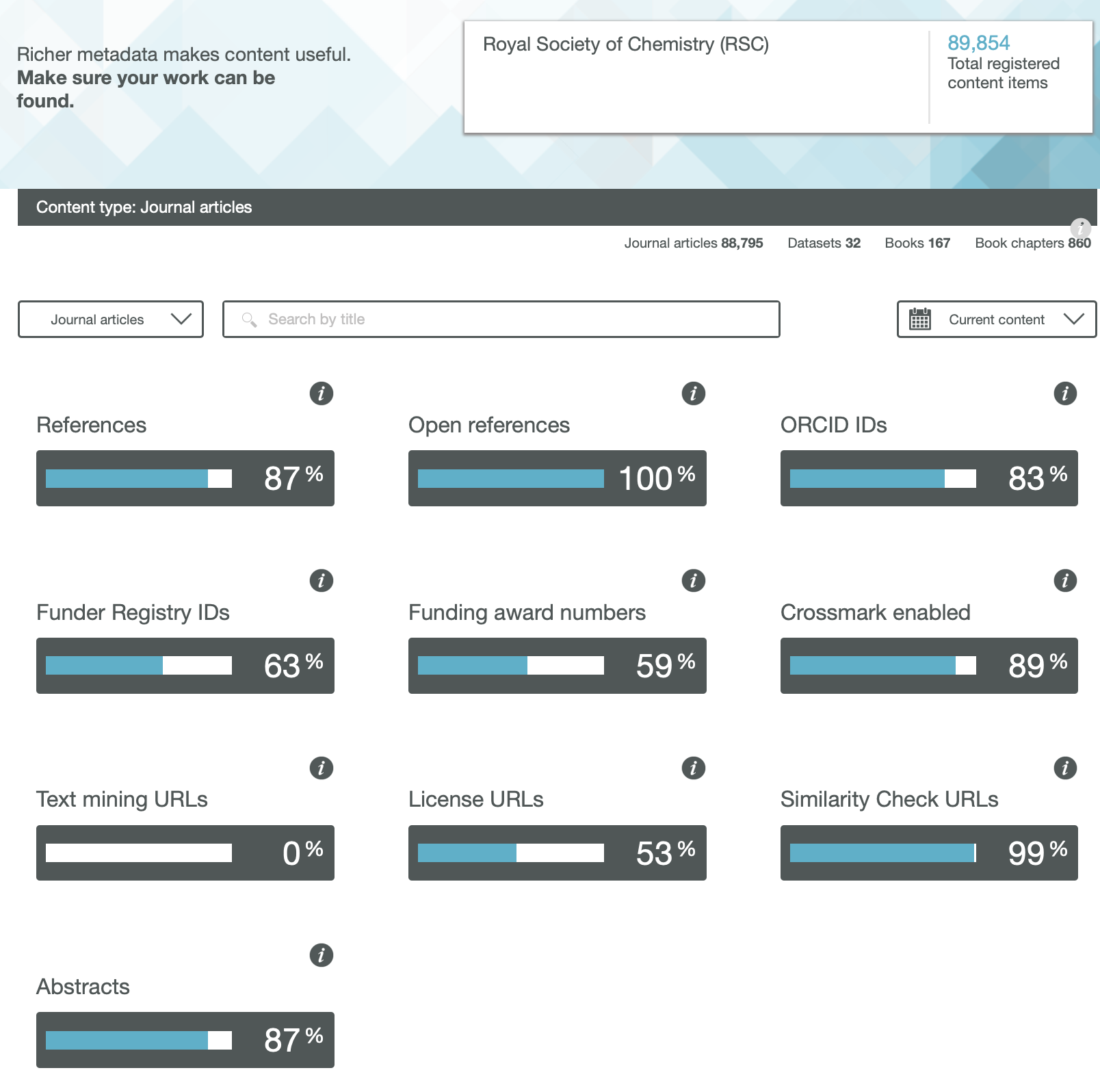
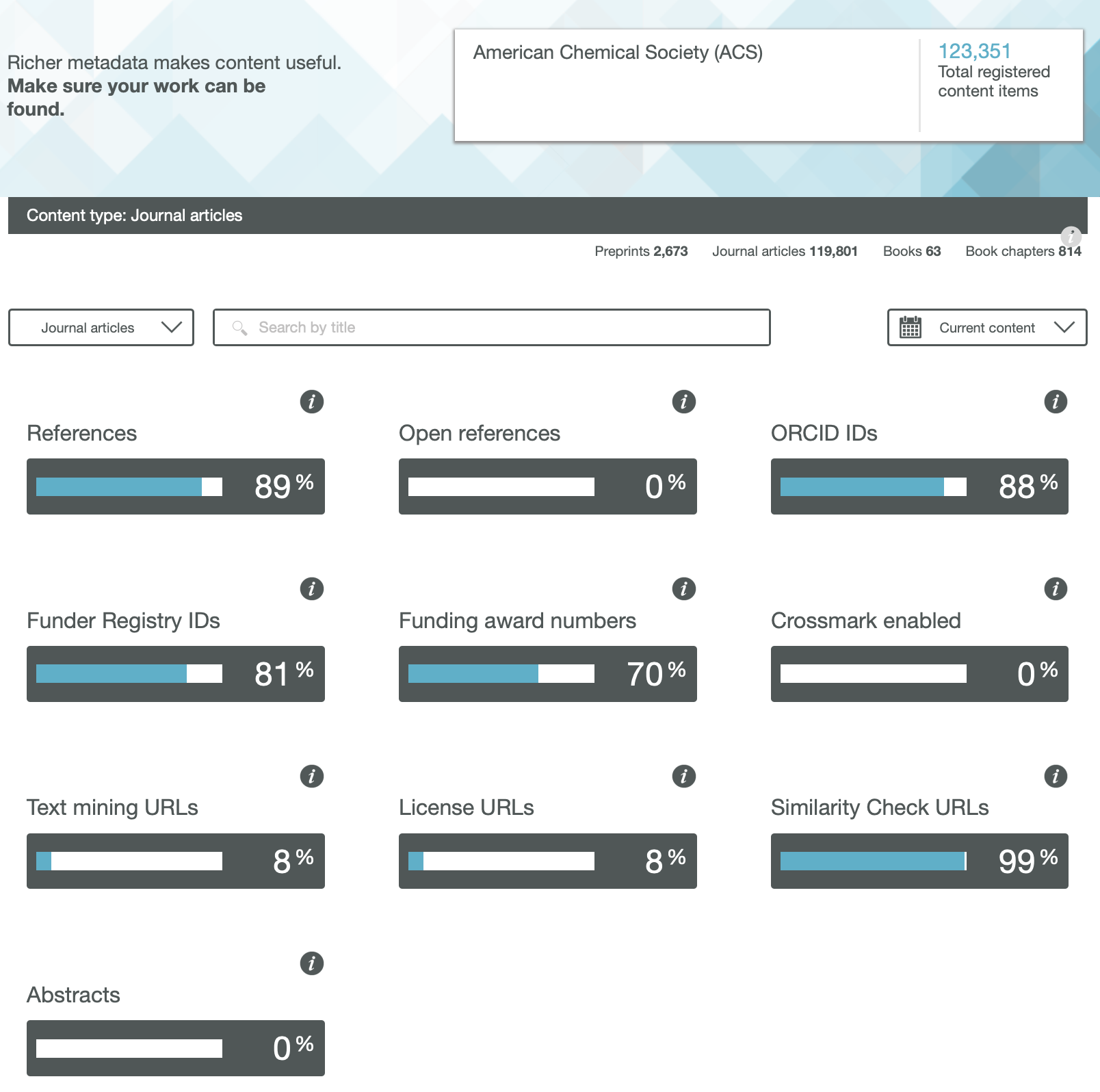
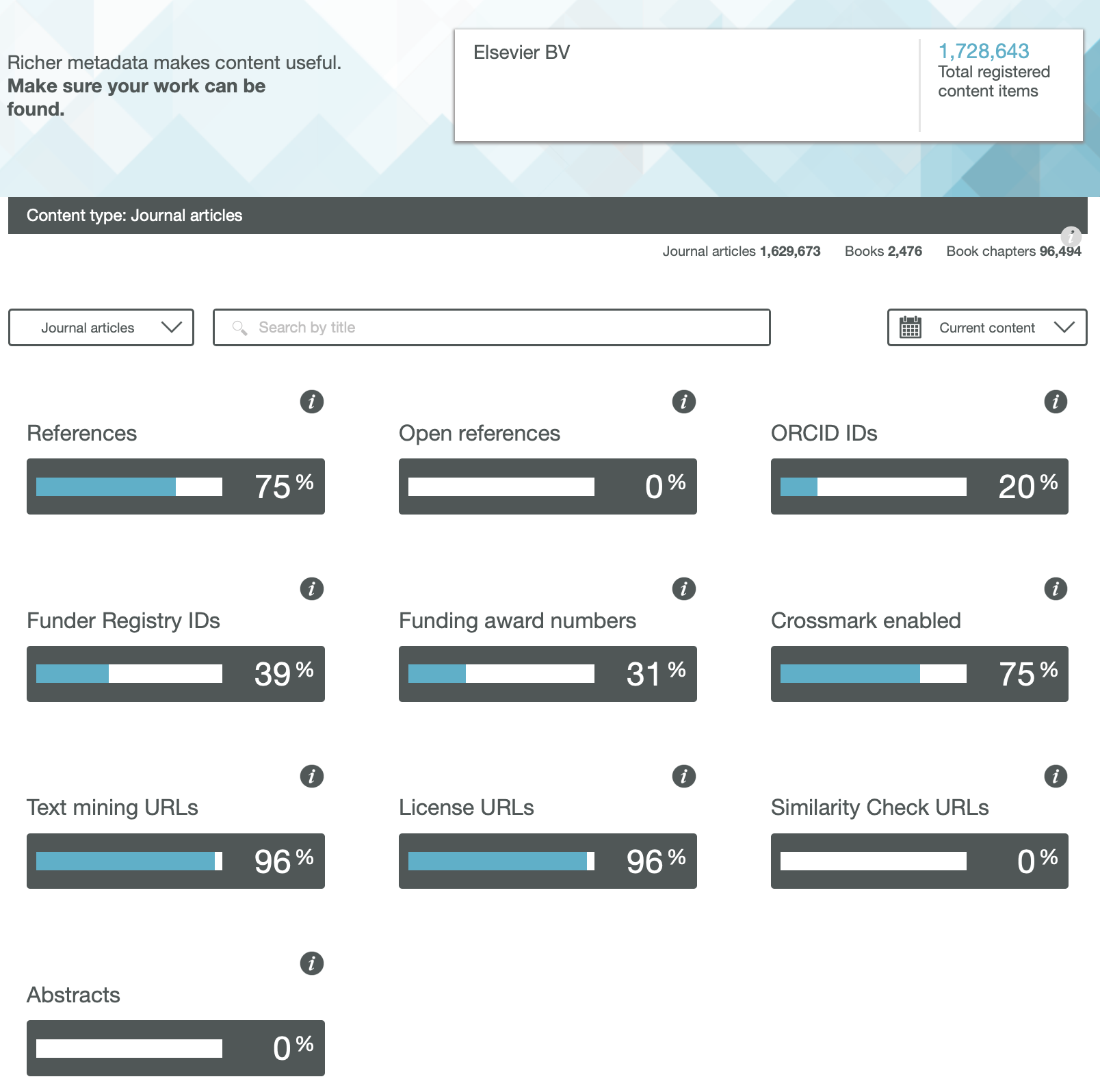
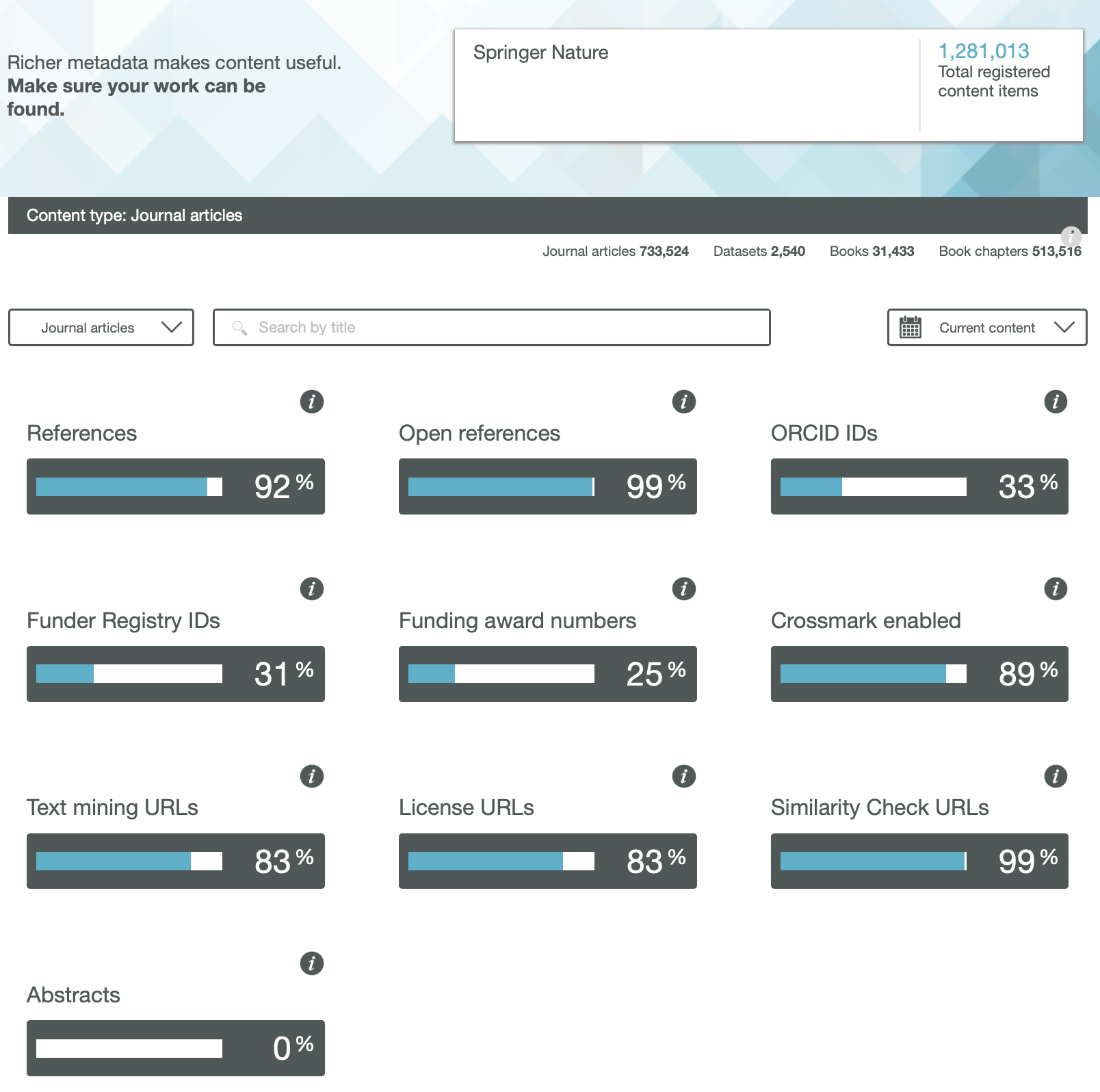
In a previous post, I looked at the Findability of FAIR data in common chemistry journals. Here I move on to the next letter, the A = Accessible.
The attributes of A[cite]10.1038/sdata.2016.18[/cite] include:
- (meta)data are retrievable by their identifier using a standardized communication protocol.
- the protocol is open, free and universally implementable.
- the protocol allows for an authentication and authorization procedure.
- metadata are accessible, even when the data are no longer available.
- The metadata should include access information that enables automatic processing by a machine as well as a person.
Items 1-2 are covered by associating a DOI (digital object identifier) with the metadata. Item 3 relates to data which is not necessarily also OPEN (FAIR and OPEN are complementary, but do not mean the same).
Item 4 mandates that a copy of the metadata be held separately from the data itself; currently the favoured repository is DataCite (and this metadata way well be duplicated at CrossRef, thus providing a measure of redundancy). It also addresses an interesting debate on whether the container for data such as a ZIP or other compressed archive should also contain the full metadata descriptors internally, which would not directly address item 4, but could do so by also registering a copy of the metadata externally with eg DataCite.
Item 4 also implies some measure of separation between the data and its metadata, which now raises an interesting and separate issue (introduced with this post) that the metadata can be considered a living object, with some attributes being updated post deposition of the data itself. Thus such metadata could include an identifier to the journal article relating to the data, information that only appears after the FAIR data itself is published. Or pointers to other datasets published at a later date. Such updating of metadata contained in an archive along with the data itself would be problematic, since the data itself should not be a living object.
Item 5 is the need for Accessibility to relate both to a human acquiring FAIR data and to a machine. The latter needs direct information on exactly how to access the data. To illustrate this, I will use data deposited in support of the previous post and for which a representative example of metadata can be found at (item 4) a separate location at:
data.datacite.org/application/vnd.datacite.datacite+xml/10.14469/hpc/5496
This contains the components:
- <relatedIdentifier relatedIdentifierType="URL" relationType="HasMetadata" relatedMetadataScheme="ORE"schemeURI="http://www.openarchives.org/ore/
">https://data.hpc.imperial.ac.uk/resolve/?ore=5496</relatedIdentifier> - <relatedIdentifier relatedIdentifierType="URL" relationType="HasPart" relatedMetadataScheme="Filename" schemeURI="filename://aW5wdXQuZ2pm">https://data.hpc.imperial.ac.uk/resolve/?doi=5496&file=1</relatedIdentifier>
Item 6 is an machine-suitable RDF declaration of the full metadata record. Item 7 allows direct access to the datafile. This in turn allows programmed interfaces to the data to be constructed, which include e.g. components for immediate visualisation and/or analysis. It also allows access on a large-scale (mining), something a human is unlikely to try.
It would be fair to say that the A of FAIR is still evolving. Moreover, searches of the DataCite metadata database are not yet at the point where one can automatically identify metadata records that have these attributes. When they do become available, I will show some examples here.
Added: This search: https://search.test.datacite.org/works?
query=relatedIdentifiers.relatedMetadataScheme:ORE shows how it might operate.