Living in London, travelling using public transport is often the best way to get around. Before setting out on a journey one checks the status of the network. Doing so today I came across this page: our open data from Transport for London.
- I learnt that by making TFL travel data openly available, some 11,000 developers (sic!) have registered for access, out of which some 600 travel apps have emerged.
- The data is in XML, which makes it readily inter-operable.[cite]10.1021/ci990052b[/cite]
- This encourages crowd-sourced innovation.
- They have taken the trouble to produce an API (application programmable interface) which allows rich access to the data and information about e.g. AccidentStats, AirQuality, BikePoint, Journey, Line, Mode, Occupancy, Place, Road, Search, StopPointVehicle.
Chemists could learn some lessons here! Of course, there are quite a few chemical databases with APIs that are examples of open data, but the “ESI” (electronic supporting information) sources which almost all published articles rely upon to disseminate data are clearly struggling to cope. Take for example this recent article[cite]10.1021/jacs.6b13229[/cite], where much of the data has been dropped into the inevitable PDF “coffin” and which is a breathtaking 907 pages long. To give the authors their due, they also provide 20 CIF files which ARE good sources of data. Rarely commented on, but clearly missing from the information associated with this (indeed most) articles is the metadata about the data. Thus the metadata for these CIF files amounts to just e.g. 229. To find out the context, one has to scour the article (or the 907 pages of the ESI) to identify compound 229 (I strongly suspect it’s a molecule because of the implied semantics of the term, not because its been explicitly declared). You will not find the metadata at e.g. data.datacite.org which is one open aggregator and global search engine based on deposited metadata.
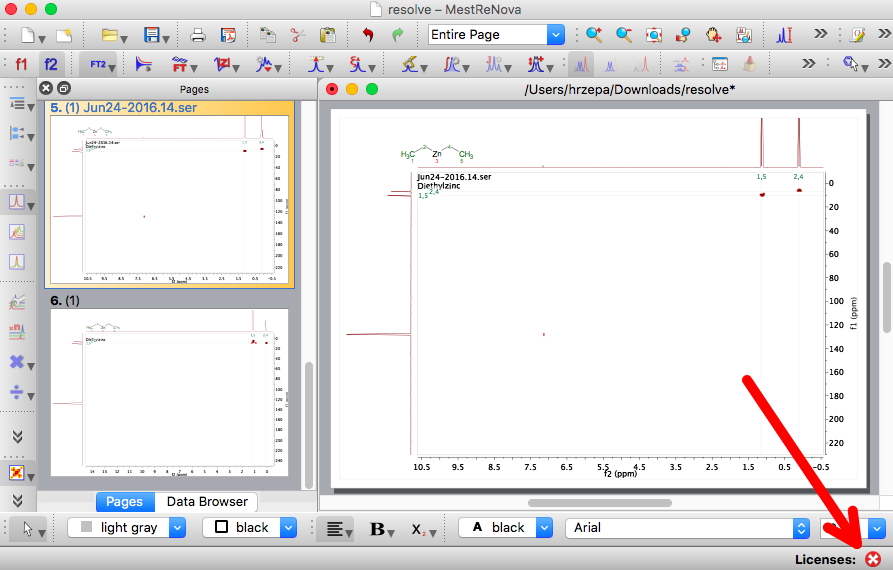
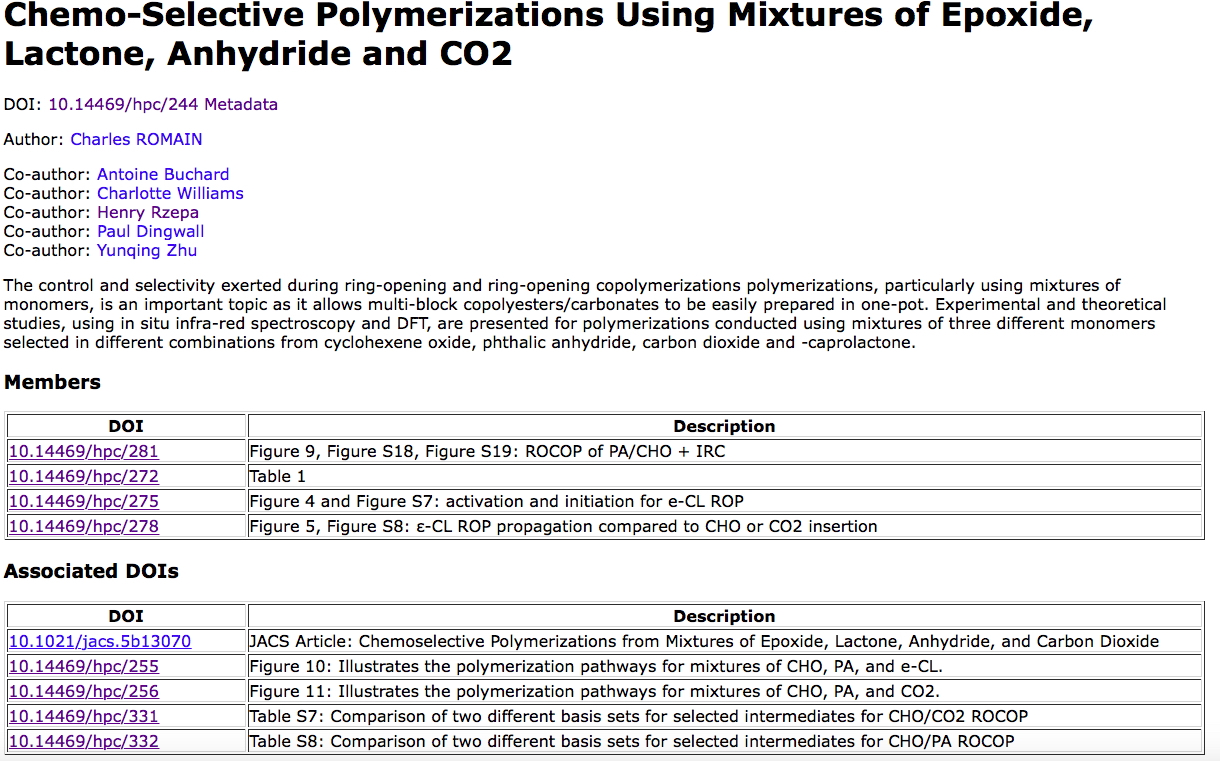
I have commented elsewhere on this blog that other types of data could also be enhanced in the manner that CIF crystallographic files represent. For example the Mpublish NMR project,‡ examples of which are shown here, and for which typical data AND its metadata can be seen at DOI: 10.14469/hpc/1053. I fancy that if this method had been adopted,[cite]10.1021/jacs.6b13229[/cite] those 907 pages might have shrunk somewhat, although of course not entirely. But my hope is that gradually the innovative chemistry community will find ways of exhuming more and more data from the PDF coffin and in the process reducing the paginated lengths of the PDF-based ESI further, perchance eventually even to zero?
If you are yourself preparing an article and sweating over the ESI at this very moment, do please take a look at the Mpublish method and how perhaps it can help make your NMR data at least more useful to others.
‡I understand an article describing this project is in preparation. If you cannot wait, this recent application of the Mpublish project has some details.[cite]10.1186/s13321-017-0190-6[/cite]