Scientists are familiar with the term data, at least in a scientific or chemical context, but appreciating metadata (meaning "after", or "beyond") is slightly more subtle, in the sense of using it to mean data about data. The challenge lies in clarifying where the boundary between data and its metadata lies and in specifying and controlling the vocabulary used for these metadata descriptions. Items in a chemical metadata dictionary might include e.g. subject classifications such as Organic Molecular Chemistry or identifiers such as InChIkey. But what could metametadata be? Here I briefly show some examples by way of illustration.
Let me start by defining a data repository as a store of both data and the metadata describing it. The metadata is to be exposed in a standard manner which allows it to be aggregated by other agencies. Nowdays, it is becoming common to identify such a data object together with its metadata using a persistent identifier, or DOI. But to decide if any particular repository and the data objects contained therein is generally useful to you, you need information about the metadata itself. Technically, this is defined using a schema[cite]10.2312/re3.008[/cite] describing the metadata (which might e.g. identify any dictionaries used); hence metametadata. Now you need to store the metametadata and so I introduce the concept of a registry which does this. This metametadata object is itself assigned a DOI‡ and here I list these DOIs for a personal selection of some chemically oriented examples, in this case deriving from the largest registry of research data repositories re3data.org. You can search for your own entry at their site: http://service.re3data.org/search.
| Data repository | The repository metametadata DOI♣ | Badge |
|---|---|---|
| Figshare | 10.17616/R3PK5R[cite]10.17616/R3PK5R[/cite] |

|
| Zenodo | 10.17616/R3QP53[cite]10.17616/R3QP53[/cite] |

|
| Cambridge structure database | 10.17616/R36011[cite]10.17616/R36011[/cite] |

|
| Crystallographic open database | 10.17616/R37S31[cite]10.17616/R37S31[/cite] |

|
|
Oxford University Research Archive |
10.17616/R3Q056[cite]10.17616/R3Q056[/cite] |

|
|
Open Notebook Science |
10.17616/R3859D[cite]10.17616/R3859D[/cite] |

|
|
Usefulchem |
10.17616/R3Z89N[cite]10.17616/R3Z89N[/cite] |

|
|
Chemotion |
10.17616/R34P5T[cite]10.17616/R34P5T[/cite] |

|
|
Chemspider |
10.17616/R38P4P[cite]10.17616/R38P4P[/cite] |

|
|
Chemical Database Service |
10.17616/R36P42[cite]10.17616/R36P42[/cite] |

|
|
Imperial College HPC data repository. |
10.17616/R3K64N[cite]10.17616/R3K64N[/cite],[cite]10.14469/hpc/382[/cite] |

|
|
Imperial College SPECTRa repository.[cite]10.1021/ci7004737[/cite] |
10.17616/R30316[cite]10.17616/R30316[/cite] |

|
Not all of the repositories listed in the table above assign formal DOIs to their data collections, meaning that the metadata for their entries cannot be aggregated in a searchable manner using e.g. search.datacite.org/ui (or search.datacite.org/api for the machine version). Currently, the metametadata does not fully carry this information, an aspect which I gather will be rectified in a future revision of the re3data schema.[cite]10.2312/re3.008[/cite]
Importantly, both metadata and (repository) metametadata can be searched using APIs (application programmer interface), ensuring that the entire flow of meta information can be subject to automated software analysis rather than just visual inspections by a human.This should allow a rich and open infrastructure for handling research objects or data to be built up using hierarchical metadata. The examples above indeed show that the chemical space is already the largest component of the Natural Sciences space.
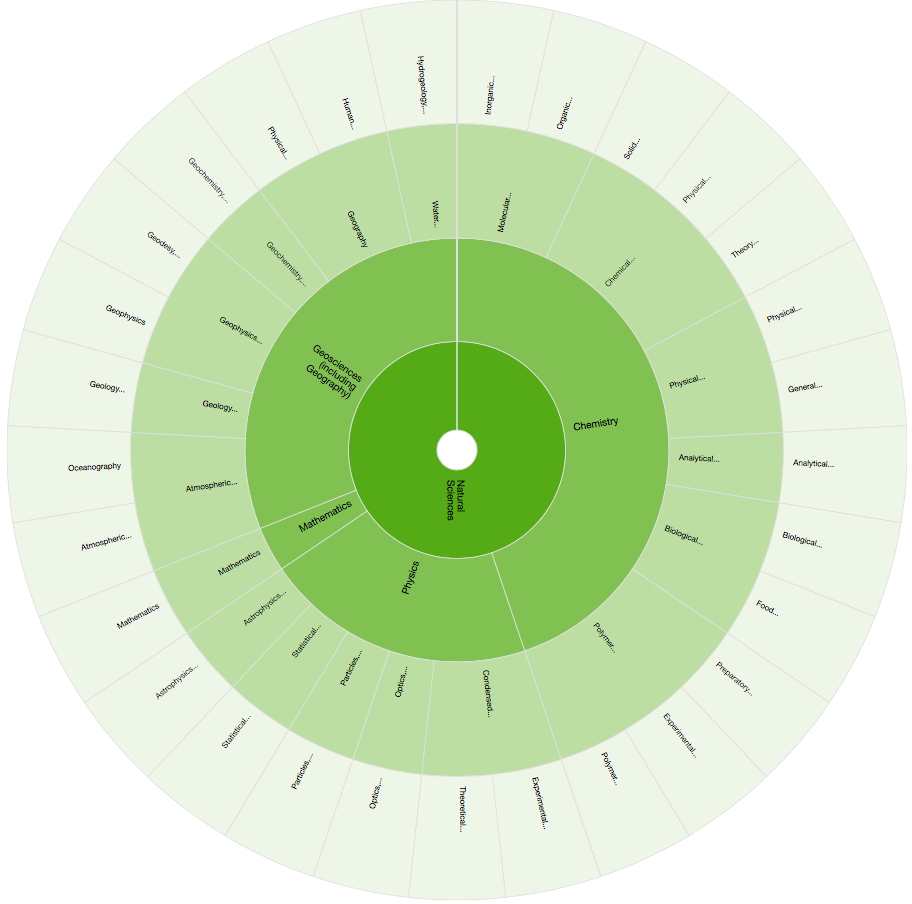
Although the edifice is still largely in its infancy, already I think we can start to see an alternative open approach emerging to "Googling" for data, or the even older traditional bespoke (i.e. non-open) services offered by commercial human-based abstractors of chemical metadata.
‡This DOI is information about the metametadata, and hence it is metametametadata, or m3data. Sorry! ♣The citations at the foot of this post are generated entirely automatically (by a WordPress plugin called Kcite) from the m3data associated with each entry, i.e. the DOI listed. Were the persistent identifier for the entry ever to be changed, this would propagate automatically to the citation, unlike the static entries in the table.